Kafka vs RabbitMQ-Choosing the Right Tool for Your Distributed Architecture
When designing a distributed architecture, selecting the right tool for message processing can make or break your system’s scalability, performance, and maintainability. Two popular tools — Apache Kafka and RabbitMQ — are often considered for handling message streams and queues, but they solve different problems and are optimized for specific use cases.
This article deep dives into the differences between Kafka and RabbitMQ, their strengths and weaknesses, common scenarios, and how to balance trade-offs in distributed systems.
Understanding Kafka and RabbitMQ

Before looking into the specifics, let’s take a look at what Kafka and RabbitMQ are
- Kafka is a distributed stream-processing system designed for high-throughput event streaming. It is optimized for real-time data streams where multiple consumers may need to access the same event.
- RabbitMQ is a message broker implementing the Advanced Message Queuing Protocol (AMQP). It is designed to queue tasks and distribute them to workers. RabbitMQ supports message acknowledgments and complex message routing.
High-Level Overview of Kafka vs. RabbitMQ

A diagram compares Kafka and RabbitMQ in terms of their Default behaviors.
- Kafka offers Stream processing, fan-out patterns, and high throughput.
- RabbitMQ offers Task queuing, point-to-point communication, and message acknowledgment.
Both can be configured to behave other way around. But it needs a bit of a setup.
Kafka Overview
Kafka is designed for event streaming and is built around the concept of a distributed commit log. Its architecture is optimized for ingesting and processing large streams of events, often referred to as publish-subscribe messaging.
How Kafka Works

- Kafka uses a topic-based model where producers write data into topics, and consumers subscribe to these topics to receive data.
- Each topic is broken into partitions, allowing Kafka to distribute load across multiple brokers (servers) for horizontal scaling.
- Kafka retains data even after it’s consumed, allowing consumers to replay events if needed. This feature is important for analytics, logging, and other use cases that require data reprocessing.
Fan-Out Pattern in Kafka
Example- You have a stream of user events coming into your system — each representing a user activity (e.g., page views, clicks, purchases). In a fan-out scenario.
- Logging Service — Writes the events to a database for long-term storage.
- Analytics Service — Analyzes user behavior in real-time.
- Notification Service — Sends real-time notifications based on user actions.
In Kafka, each of these services (consumers) can read the same stream of events from the Kafka topic, as Kafka supports a fan-out pattern by default. This means all services get the same data stream and can process it independently.
Key Kafka Features
- High Throughput — Kafka is designed to handle millions of messages per second with low latency.
- Fan-Out by Default — Kafka’s pub-sub architecture allows the same event to be consumed by multiple consumers.
- Data Persistence — Kafka stores data for a configurable amount of time (time-to-live), which enables message replay and fault tolerance.
RabbitMQ Overview
RabbitMQ is a message queuing system that follows a traditional point-to-point messaging model. It is designed for task-based systems where messages are delivered to specific consumers based on routing logic.
How RabbitMQ Works
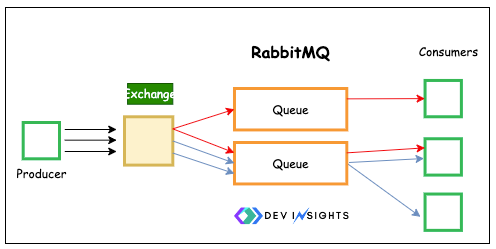
- RabbitMQ uses queues to temporarily store messages. Producers send messages to an exchange, which routes them to queues based on predefined rules (e.g., headers, topics).
- Consumers subscribe to queues and process the messages. Once a message is consumed, it is removed from the queue, ensuring that each message is processed only once.
- RabbitMQ supports message acknowledgment, ensuring that messages are only marked as delivered when fully processed.
Task Processing in RabbitMQ
Example — You have a job processing system where tasks are added to a queue, and worker nodes pick up and process tasks as they become available. Each task only needs to be processed by one worker:
- The Producer adds tasks to the RabbitMQ queue.
- Multiple Worker Nodes are connected to the queue, each processing one task at a time. If a worker fails to process the task, the task is re-queued for another worker.
In this case, RabbitMQ ensures that each task is handled by only one worker node, providing task acknowledgment to ensure no task is lost if a failure occurs.
Key RabbitMQ Features
- Message Routing — RabbitMQ excels at complex message routing. It supports direct, topic, fan-out, and header exchanges, allowing messages to be routed based on properties like message content.
- Message Acknowledgment — Consumers can acknowledge messages upon successful processing, and RabbitMQ will resend messages if acknowledgments aren’t received within a timeout.
- Handling Sporadic Workloads — RabbitMQ is great for bursty or irregular workloads, where tasks may arrive in unpredictable patterns.
Kafka vs RabbitMQ

Kafka Implementation
In Kafka, messages are partitioned and replicated across brokers, allowing for high throughput and redundancy. When implementing Kafka, you typically deal with
- Producers writing to topics and specifying partition keys.
- Consumers subscribe to topics and read messages based on offsets, allowing them to replay messages.
- Partitions distributing data across multiple brokers for scaling.
Scenario — An e-commerce company using Kafka for real-time clickstream data processing. Each user action (e.g., clicks, searches) is sent to Kafka and distributed to multiple consumers, such as:
- A real-time recommendation engine.
- A fraud detection system.
- A logging service for audit trails.
RabbitMQ Implementation
RabbitMQ provides fine-grained control over message routing and processing. It supports multiple exchange types (direct, fan-out, topic) for flexible routing. You’ll need to define:
- Producers send messages to exchanges, which route them to queues.
- Consumers subscribing to queues and acknowledging message receipt.
- Exchanges define how messages are routed to different consumers.
Scenario — A payroll system using RabbitMQ to process salary calculations. Each task represents a payroll calculation for an employee:
- RabbitMQ queues tasks and ensures each worker processes one payroll task.
- If a worker fails, RabbitMQ re-queues the task for another worker.
Trade-offs Between Kafka and RabbitMQ
When deciding between Kafka and RabbitMQ, consider these trade-offs.
1. Message Throughput vs. Reliability
- Kafka — Optimized for high throughput, Kafka supports processing millions of messages per second. However, it doesn’t guarantee message delivery in the same way RabbitMQ does.
- RabbitMQ — Focuses on reliability and ensures each message is delivered and acknowledged, making it ideal for tasks where losing messages is not acceptable.
2. Fan-Out vs. Point-to-Point
- Kafka — Ideal for fan-out patterns, Kafka allows multiple consumers to process the same message stream independently.
- RabbitMQ — Best suited for point-to-point communication, where each message is processed by exactly one consumer.
3. Data Replay vs. One-Time Processing
- Kafka — Supports message replay, allowing consumers to reprocess past events.
- RabbitMQ — Once a message is consumed, it’s gone. This is useful for tasks that need to be processed exactly once, such as job queues.
4. Real-Time Streaming vs. Task Queuing:
- Kafka — Designed for real-time event streaming where latency is crucial.
- RabbitMQ — Great for task processing where messages represent tasks that may take time to complete.
Choosing the Right Tool for Your Distributed Architecture
When building a distributed system, your choice between Kafka and RabbitMQ depends on the specific requirements of your system
- Choose Kafka if you’re dealing with high-throughput, real-time event streams that need to be consumed by multiple services or systems.
- Choose RabbitMQ if you need reliable task processing, complex routing, or message acknowledgment for individual consumers.
If you enjoyed this article and found it insightful, please consider supporting it with some 👏 claps, sharing it 🔄, and following me on LinkedIn 🔗. I value your feedback and would love to hear your opinions and ideas 💡. Don’t hesitate to comment below with topics you’re interested in or thoughts you’d like to share 💬. Let’s keep the conversation going and explore together!
Are you looking for expert freelance services or professional consultation? Visit https://devinsights.tech/ for top-notch solutions tailored to your needs. Let’s turn your vision into reality!
